|
UN LISTADO DE LAS SÍLABAS
DEL ESPAÑOL
JERÓNIMO ARMARIO TORO
Diplomado en Magisterio
Licenciado en Psicopedagogía
Las posibilidades que ofrece el tratamiento informatizado de los datos permite,
hoy día, realizar investigaciones y recopilaciones a personas no especialistas,
las cuales, en otro tiempo, hubieran sido obra de eruditos o denodados y curiosos
coleccionistas. En este artículo presentamos el proceso seguido para la
obtención de un listado de las sílabas del español, el cual,
además de su propio interés teórico, mostrará varias
aplicaciones prácticas.
El objetivo principal de este artículo es el de hacer público
el resultado de una investigación que nos ha llevado a realizar un listado,
esperamos que totalmente completo, de todas las sílabas del español.
En efecto, este listado de sílabas será lo que presentemos en subsiguientes
entregas, ordenadas convenientemente en una tabla en la que, debido a consideraciones
de espacio, sólo aparecerán estas últimas sílabas,
sin las palabras que las ejemplifican.
No obstante, creemos también sumamente interesante, y esperamos que
de gran provecho para el lector, mostrar de forma complementaria el proceso seguido
hasta su obtención, así como dar ejemplo sobre cómo el uso
de la programación informática y el tratamiento informatizado de
textos puede convertirse en un medio que amplía significativamente las
posibilidades del lingüista investigador.
Introducción
Si se preguntase a un adulto cualquiera sobre un listado de todas las sílabas
posibles de la lengua española, con todas sus combinaciones posibles, es
muy posible que tuviésemos que contentarnos con la contestación
de que serían muchas. Ante la insistencia sobre un número más
concreto, una persona avispada contaría las letras del abecedario (29 según
la Ortografía de la Lengua Española de la RAE) y, tras promediar
entre dos y tres letras por sílaba, nos arrojaría un número
entre 841 (29*29) y 24.389 (29*29*29). A este número habría que
descontar, por supuesto, aquellas combinaciones imposibles, a la vez que añadir
aquellas sílabas con más de tres letras o con una sola de ellas.
Si tuviésemos en cuenta que el núcleo silábico lo constituye
siempre una vocal, podríamos aventurar entre 120 ((29-5)*5 = consonante
+ vocal) y 3.480 ((29-5)*5*29 = consonante + vocal + letra), a falta de eliminar
combinaciones imposibles, y ampliarla con sílabas de más de tres
letras y otras variantes. Nótese que hemos tenido en cuenta algunos posibles
diptongos al no eliminar todas las vocales del último multiplicando. Pero,
żestaríamos en lo cierto? żPodríamos asegurar unos números
así? żSerían pocos, o bien nos habríamos excedido sobremanera?
Curiosamente, el límite superior no estaría muy alejado del número
que hemos obtenido. Es más, sería una más que aceptable aproximación
y solución al problema, a falta de un sistema de recopilación practicable.
Otra posible estrategia sería buscar bibliografía al respecto.
Sin embargo, si así se hiciese, en ella encontramos estudios sobre la sílaba,
sobre la frecuencia de aparición de sus diferentes tipos (Consonante+Vocal,
CVC, V, VC, etc.. Guerra, 1981, citado por Quilis, 1993) pero, żqué sobre
su número y cuáles fueran todas ellas? żA qué persona podría
ocurrírsele entretenerse en algo así? Conocer el listado exacto
de todas las sílabas del español podría parecer más
el deseo coleccionista de un niño que la empresa de una persona razonable,
a no ser que sea éste un experto y curioso investigador, o quizás
un adulto que no ha perdido aún ese afán y pureza investigadora
infantil.
Lejos de visiones tan románticas, en este artículo deseamos mostrar
cómo, en realidad, hoy día esto no tiene necesariamente por qué
ser así, y queremos iluminar nuevos procedimientos que puedan conducir
a los lingüistas a explorar las nuevas posibilidades y herramientas que los
medios automatizados ponen a nuestra disposición.
Los orígenes de la empresa
La idea de la obtención de un listado de las sílabas del español
surgió como la aplicación de parte de un programa de ordenador creado
para otros fines, como lo fue un programa educativo que permitía al alumno
o usuario introducir una poesía o texto en la parte derecha de la pantalla
del ordenador, mientras que en la porción izquierda aparecía el
mismo texto, pero esta vez descompuesto en sus sílabas constituyentes,
junto con un recuento del número de las sílabas que componían
cada verso. Esta conversión se realizaba de forma automática, de
modo que resultaba curioso observar cómo se iba construyendo el texto descompuesto,
al mismo tiempo que se tecleaban e introducían las palabras en el ordenador.
Como es obvio, su aplicación didáctica estribaba en la facilitación
de la construcción de poesías y, por extensión, permitía
explorar sin engorro la evidencia de una secuencia numérica inamovible
en distintos tipos de estrofa que son parte constituyente de gran parte de las
poesías. El alumno tendría, claro está, que tener en cuenta
las posibles licencias poéticas, con el fin de poder cuadrar los números
en ciertas estrofas.
Para llevar a cabo la conversión, el programa tenía necesidad
de una rutina, es decir, un pequeño programa o porción de
código, en el argot informático informal, el cual recibía
como entrada una palabra de la lengua española y devolvía esa misma
palabra, pero descompuesta en sílabas. Esta rutina constituía el
corazón del programa, y se trataba de un módulo que permite ser
incorporado a diversos programas de ordenador más amplios, que poseen también
variados y múltiples cometidos.

No fue difícil vislumbrar nuevas aplicaciones a esta
rutina. Siguiendo una extensión natural de su funcionamiento, la rutina
fue incorporada a un programa que tomaba archivos de texto de ordenador (véase
como ejemplo el fichero TEXTO.TXT en el diagrama), y devolvía el mismo
texto dividido en sílabas (SALIDA.TXT). Con posterioridad, se modificó
el programa para que produjese diferentes tipos de ficheros de salida, entre los
cuales el más interesante para nuestros propósitos resultó
ser aquél que colocaba cada sílaba en una línea, junto a
la palabra completa de la que procedía a su lado (SALIDA2.TXT).
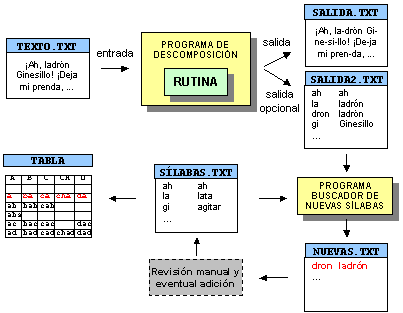
De aquí tomamos, precisamente, la idea de realizar una recopilación
de las sílabas del español.
Como se puede observar, esta disposición da pie inmediatamente a la
creación de un programa que lea tales líneas del fichero con formato
de salida opcional (SALIDA2.TXT) y, al compararlas con una lista (SILABAS.TXT)
de sílabas ya conocidas, envíe a un nuevo fichero (NUEVAS.TXT) cada
nueva sílaba encontrada, junto con la indicación de la palabra de
la que procede.
A la búsqueda de las sílabas del español
No nos demoramos pues, ante la curiosidad, en construir todo el dispositivo
informático. Una vez realizado, la cuestión se reducía a
alimentar toda esa "fábrica informática" de sílabas
con un número ingente de su materia prima: amplios ficheros de textos los
cuales contuviesen grandes cantidades de palabras.
Así, como es obvio, la primera idea que tuvimos fue la de introducir
un fichero de texto que contenía todas las palabras del DRAE. Como consecuencia
de esto, se obtuvo un listado con un número importante de sílabas
que fueron luego comprobadas minuciosamente de forma manual. Esto permitió,
además, corregir algunos defectos desconocidos en la descomposición
silábica de la rutina en determinadas palabras extranjeras, pero asimiladas,
o de difícil segmentación.
Llegados a este punto, sabíamos que aún no contábamos
con un listado completo. Obviamente, en las palabras listadas en el diccionario
de la RAE no concurren verbos flexionados, ni plurales, ni otras derivaciones
y variantes, que podrían aportar nuevas sílabas a nuestro listado.
Procedimos, entonces, a introducir el texto perteneciente a los 36.070
artículos de la enciclopedia Encarta 99, lo cual produjo ingentes ficheros
de sílabas supuestamente novedosas, entre los que ciertamente se encontraban
muchas legítimas, pero también otras procedentes de palabras técnicas,
anglicismos, nombres propios procedentes de otros idiomas, y un largo etcétera.
Presentamos un pequeño ejemplo, y dejamos al lector dar cuenta sobre cuáles
incluiría y cuáles no:
| [...] |
|
|
|
|
|
|
|
| roc |
 |
suroccidental |
|
duk |
|
marduk |
|
| guei |
|
jongueiro |
|
wurz |
|
wurzburgo |
|
| jof |
|
joffre |
|
prat |
|
prats |
|
| b |
|
ACB |
|
joc |
|
joc |
|
| dous |
|
maridóus |
|
tius |
|
laetius |
|
| bye |
|
bye |
|
wit |
|
witwatersrand |
|
|
|
|
|
|
|
[...] |
|
Como se puede evidenciar, surgen dudas que aconsejan incorporar algunas de
esas sílabas en diferentes compartimentos, a falta de ser halladas en otras
palabras con una mayor difusión en nuestra lengua. Con lentitud, se fueron
incorporando las nuevas adquisiciones. Además, se introdujeron textos de
distinta índole y procedencia, así como tablas de verbos conjugados.
Los resultados
Todo este proceso culminó con la obtención de un listado
que quedó ordenado de la siguiente manera:
1. APARTADO GENERAL DE SÍLABAS "CORRIENTES"
2.236 + 4 sílabas
2. APARTADOS ESPECÍFICOS
Sílabas
sólo atribuibles a...
| ... morfemas verbales: |
|
238 + 4 sílabas |
| ... plurales: |
|
44 + 1 sílabas |
| ... palabras compuestas: |
|
0 + 77 sílabas |
... nombres propios, apellidos,
gentilicios,
topónimos, |
|
0 + 42 sílabas |
| ... palabras latinas del DRAE: |
|
0 + 12 sílabas |
El primer sumando indica el número de sílabas que se han incluido
en el apartado de que se trate y que, además, aparecen en la tabla de la
que hablaremos más adelante. El segundo número indica las sílabas
que se han incluido también en ese apartado, o bien que son susceptibles
de ser incluidas en él, ya sea porque, por el momento, se mantienen dudas
sobre ellas, o por otras causas que se indican junto a la sílaba en cuestión
(sílabas extrañas al español, procedentes del quechua, náhuatl,
palabras compuestas, neologismos, anglicismos, etc.). Estas sílabas no
aparecen en la tabla.
Como se puede observar, hemos obtenido un listado de aproximadamente unas
2518 sílabas, número variable según distintos criterios,
con su correspondiente palabra que ejemplifica la inclusión de cada sílaba
y anotaciones, que indican si es la única palabra que la contiene o, si
son pocas, una lista de cuáles son esas palabras. Asimismo, se indican
otras circunstancias especiales, como se mencionó en el párrafo
anterior. Se trata de un amplio listado de 47 páginas, que cae fuera de
los límites de una publicación de estas características.
Se muestra un breve ejemplo a continuación:
| [...] |
|
|
|
|
| be |
|
nube |
|
|
| beb |
|
bebdez |
|
(familia, únicas) |
| bec |
|
lobectomía |
|
becqueriano (unicas) |
| bei |
|
albeitar |
|
(familia), beicon, beige, ribeiro (únicas) |
| beis |
|
habéis |
|
beis, béisbol (únicas) y terminaciones verbales. |
| [...] |
|
|
|
|
Desgraciadamente, esas anotaciones aún no han sido finalizadas a la
fecha de redacción de este artículo, al tratarse de un proceso manual
de gran lentitud.
Obsérvese, de igual manera, la gran cantidad de sílabas que
solamente, y remarcamos la palabra "solamente", hemos encontrado en
morfemas verbales, pareciendo éste un fenómeno notable y merecedor
de futuras investigaciones que lo expliquen con detenimiento.
Por último, se creó una tabla ordenada con el contenido de
todas las sílabas halladas, cuestión muy interesante, pues constituye
como una especie de mapa genético de la formación de las palabras
castellanas, y permite hacerse nuevas preguntas como, por ejemplo, acerca de los
espacios ausentes.
Es la lista que reproduciremos en varias entregas y que habla por sí
sola.
Por otra parte, este listado está siendo actualmente valorado por la
RAE, y esperamos sea de provecho para la nueva edición de su Gramática
Oficial, que ésta prepara en la actualidad.
 Ver
tabla (194 Kb) Ver
tabla (194 Kb)
Interés de la investigación
Como puede preverse, el listado obtenido es de interés tanto en el ámbito
teórico como en el práctico.
En el teórico, aparte del interés intrínseco y desinteresado
de su simple posesión, permite el análisis de la frecuencia de aparición
de las sílabas en diferentes tipos de textos (narrativos, discursivos,
etc.). También el análisis de la frecuencia de aparición
de combinaciones de sílabas, lo cual podría evidenciar preferencias
psicológicas, articulatorias e incluso evolutivas del lenguaje en general,
y del español en particular. Además, también permite el análisis
automático de la frecuencia de aparición en situación tónica
o átona, y de las cadencias y ritmos en textos narrativos o líricos.
Por último, el hecho de que exista una rutina que descomponga de forma
exacta cualquier palabra castellana en sus sílabas constituyentes supone
que existe un procedimiento o regla exacta para descomponer con éxito cualquier
palabra española en sílabas, incluso sin conocer su pronunciación,
con la única condición de que se encuentre bien escrita y acentuada.
Para mayor evidencia de todo lo dicho, pueden consultarse los capítulos
dedicados a la sílaba por el Sr. Alarcos Llorach (1994) y el Sr. Quilis
(1993). El autor espera mostrar en un futuro próximo las conclusiones derivadas
del desarrollo de las posibilidades de investigación mencionadas.
Con respecto al interés práctico, además de la posibilidad
de poder dividir de forma automática cualquier palabra castellana en las
sílabas que la conforman, permite la división automática
de las palabras en morfemas, y con ello la posibilidad del reconocimiento automático
de la parte de la oración a que pertenece una palabra, siguiendo de esta
manera un sistema diferente a la consulta en una gran base de datos. Permite la
mejora de la síntesis artificial de la voz, al partir de unidades silábicas
conocidas. Por último, y no menos interesante, conduce de forma trivial
a la trascripción fonética automática, lo cual puede prologar
a las mismas investigaciones teóricas anteriormente mencionadas pero, en
esta ocasión, con el referente fonológico, no ortográfico.
Conclusión
Con la exposición realizada en este artículo pretendemos
hacer público el listado conseguido de sílabas del español.
Sin embargo, queremos también llamar la atención sobre las posibilidades
de investigación que brinda el tratamiento automatizado de datos a los
investigadores de la lengua.
Bibiografía
- Quilis, A., Tratado de Fonología y Fonética
Españolas. Ed. Gredos. Madrid, 1993.
- Hála,
B., La Sílaba: su naturaleza, su origen y sus transformaciones.
Madrid. CSIC. Collectanea Phonetica, III. Madrid, 1973.
- Alarcos
Llorach, E., Gramática de la Lengua Española. Madrid. Ed.
Espasa Calpe. Madrid, 1994.
|






